
當(dāng)前,基于邊緣智能計(jì)算設(shè)備運(yùn)行的人工智能應(yīng)用日趨復(fù)雜及高精度,為降低邊緣設(shè)備運(yùn)行的延遲和功耗,存算一體技術(shù)被應(yīng)用在邊緣設(shè)備端,通過(guò)減小數(shù)據(jù)搬運(yùn)的開(kāi)銷(xiāo)最大化減少邊緣設(shè)備上的延遲與功耗。但傳統(tǒng)的存算一體宏僅支持使用整數(shù)型數(shù)據(jù)計(jì)算,難以支持日趨高精度、高復(fù)雜度以及片上訓(xùn)練的邊緣端智能計(jì)算任務(wù)。且僅使用單一模擬或數(shù)字方案的存算一體宏,在能量效率、面積效率和精度上難以取得最優(yōu)化。如何有效結(jié)合模擬存算與數(shù)字存算模式優(yōu)勢(shì),在總體上取得更高的能量效率和面積效率,同時(shí)盡可能保證高精度,以及如何探索數(shù)模混合方案的設(shè)計(jì)空間,仍然是存算一體宏領(lǐng)域繼續(xù)解決的問(wèn)題。
針對(duì)以上問(wèn)題,中國(guó)科學(xué)院微電子研究所劉明院士團(tuán)隊(duì)研發(fā)出基于外積運(yùn)算的數(shù)模混合存算一體宏芯片,設(shè)計(jì)了一種數(shù)模混合浮點(diǎn) SRAM 存內(nèi)計(jì)算方案,提出了模擬與數(shù)字存算宏的混合方法,結(jié)合了使用模擬存算方案進(jìn)行高效陣列內(nèi)位乘法和使用數(shù)字存算方案進(jìn)行高效陣列外多位移位累加的優(yōu)點(diǎn),達(dá)到整體上高能量效率與面積效率。通過(guò)殘差式數(shù)模轉(zhuǎn)換器架構(gòu),使數(shù)模轉(zhuǎn)換器所需分辨率僅為輸入位精度的對(duì)數(shù),實(shí)現(xiàn)了高吞吐率和低開(kāi)銷(xiāo)。通過(guò)基于矩陣外積計(jì)算數(shù)學(xué)原理的浮點(diǎn)/定點(diǎn)存算塊架構(gòu),矩陣-矩陣-向量計(jì)算可通過(guò)累加器元件完成。同之前的數(shù)字存算方案使用矩陣內(nèi)積原理的大扇入、多級(jí)加法器樹(shù)相比,吞吐率更高。該架構(gòu)還支持細(xì)粒度的非結(jié)構(gòu)激活稀疏性以進(jìn)一步提升總體能效。該存算一體宏芯片在28nm ?CMOS工藝下流片,可支持BF16浮點(diǎn)精度運(yùn)算以及INT8定點(diǎn)精度運(yùn)算,BF16浮點(diǎn)矩陣-矩陣-向量計(jì)算峰值能效達(dá)到了72.12TFLOP/W,INT8定點(diǎn)矩陣-矩陣-向量計(jì)算峰值能效達(dá)到了111.17TFLOP/W。這一研究結(jié)果為采用數(shù)模混合方案的存算一體架構(gòu)芯片提供了新思路。
近期,本工作以“A 28nm 72.12TFLOPS/W Hybrid-Domain Outer-Product Based Floating-Point SRAM Computing-in-Memory Macro with Logarithm Bit-Width Residual ADC”為題發(fā)表在 ISSCC 2024國(guó)際會(huì)議上,微電子所博士生袁易揚(yáng)為第一作者,張鋒研究員與北京理工大學(xué)王興華教授為通訊作者。該研究得到了科技部重點(diǎn)研發(fā)計(jì)劃、國(guó)家自然科學(xué)基金、中國(guó)科學(xué)院戰(zhàn)略先導(dǎo)專(zhuān)項(xiàng)等項(xiàng)目的支持。
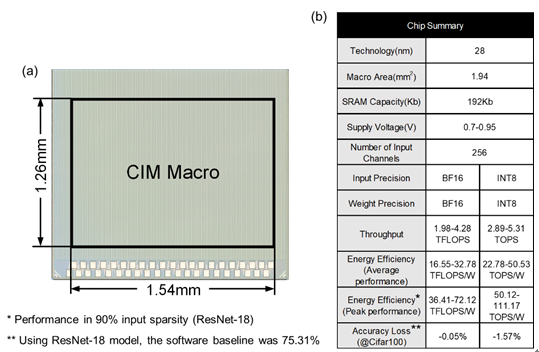
28nm 基于外積的數(shù)模混合浮點(diǎn)存算一體宏芯片:(a)芯片顯微鏡照片,(b)芯片特性總結(jié)表
| 相關(guān)新聞: |
| 微電子所在片上學(xué)習(xí)存算一體芯片方面取得重要進(jìn)展 |
| 微電子所在IGZO 2T0C DRAM多值存儲(chǔ)領(lǐng)域取得重要進(jìn)展 |
| 微電子所在鉿基鐵電存儲(chǔ)器芯片研究領(lǐng)域取得重要進(jìn)展 |


京公網(wǎng)安備110402500036號(hào)
© 中國(guó)科學(xué)院微電子研究所 版權(quán)所有
地址:北京市朝陽(yáng)區(qū)北土城西路3號(hào) 郵編:100029
郵箱:icac@ime.ac.cn
綜合新聞