
在IEEE年度Hot Chips大會(huì)上,特斯拉的FSD芯片是眾多出色的演講之一。在今年4月的自動(dòng)駕駛?cè)眨厮估状喂_(kāi)了他們的全自動(dòng)駕駛(FSD)芯片。而在最近的Hot Chips 31大會(huì)上,特斯拉對(duì)芯片的一些關(guān)鍵組件提供了一些新的見(jiàn)解。

特斯拉工程師為FSD芯片和平臺(tái)制定了許多主要目標(biāo)。他們希望在功率范圍內(nèi)盡可能多地提升芯片TOPS。為了安全起見(jiàn),芯片的主要設(shè)計(jì)點(diǎn)是在批量為一的情況下芯片的高利用率。值得注意的是,F(xiàn)SD芯片隨附了一組用于通用處理的CPU和一個(gè)用于后處理的輕量級(jí)GPU,這不在本文的討論范圍之內(nèi)。這些組件已在我們的主要文章中詳細(xì)介紹。
神經(jīng)處理器
盡管芯片上的大多數(shù)邏輯都使用經(jīng)過(guò)行業(yè)驗(yàn)證的IP塊來(lái)降低風(fēng)險(xiǎn)并加快開(kāi)發(fā)周期,但特斯拉FSD芯片上的神經(jīng)網(wǎng)絡(luò)加速器是特斯拉硬件團(tuán)隊(duì)完全定制的設(shè)計(jì)。它們也是芯片上最大的組件,最重要的邏輯部分。 特斯拉談到的一個(gè)有趣的小插曲是模擬。在開(kāi)發(fā)過(guò)程中,特斯拉希望通過(guò)運(yùn)行自己的內(nèi)部神經(jīng)網(wǎng)絡(luò)來(lái)驗(yàn)證他們的NPU性能。因?yàn)樗麄冊(cè)谠缙跊](méi)有準(zhǔn)備好仿真環(huán)境,所以他們求助于使用開(kāi)源的Verilator模擬器,他們說(shuō)這個(gè)模擬器的運(yùn)行速度比商業(yè)模擬器快50倍。“我們廣泛使用Verilator來(lái)證明我們的設(shè)計(jì)非常好,”特斯拉自動(dòng)駕駛儀硬件高級(jí)總監(jiān)Venkataramanan說(shuō)。 每個(gè)FSD芯片內(nèi)部有兩個(gè)相同的NPU,它們物理上彼此相鄰集成。當(dāng)被問(wèn)及使用兩個(gè)NPU實(shí)例而不是一個(gè)更大的單元的原因時(shí),特斯拉指出,每個(gè)NPU的大小都是物理設(shè)計(jì)(時(shí)序,面積,布線)的最佳選擇。

ISA
NPU是具有亂序內(nèi)存子系統(tǒng)的有序計(jì)算機(jī)。總體設(shè)計(jì)有點(diǎn)像是一種狀態(tài)機(jī)。ISA包含最多4個(gè)帶有復(fù)雜值的插槽的指令。總共只有八條指令:兩條DMA讀寫(xiě)指令、三條點(diǎn)積運(yùn)算指令、縮放指令和元素添加指令。NPU只是簡(jiǎn)單地運(yùn)行這些命令,直到點(diǎn)擊停止命令停止它。還有一個(gè)額外的參數(shù)槽(parameters slot )可以改變指令的屬性(例如,卷積運(yùn)算的不同變化)。有一個(gè)標(biāo)志槽(flags slot),用于處理數(shù)據(jù)依賴(lài)項(xiàng)(dependencies handling)。還有另一個(gè)擴(kuò)展插槽,這個(gè)插槽存儲(chǔ)了整個(gè)微程序序列的命令,這些命令在進(jìn)行復(fù)雜的后處理時(shí)將被發(fā)送到SIMD單元。因此,指令從32字節(jié)到非常長(zhǎng)的256字節(jié)不等。稍后將更詳細(xì)地討論SIMD單元。

初始操作
NPU的程序最初駐留在內(nèi)存中。它們被帶入NPU,并存儲(chǔ)在命令隊(duì)列中。NPU本身是一種非常出色的狀態(tài)機(jī),旨在大大減少控制開(kāi)銷(xiāo)。令隊(duì)列中的命令將被解碼為原始操作,并提供一組用于數(shù)據(jù)需要從何處獲取的地址—這包括權(quán)重和數(shù)據(jù)。例如,如果傳感器是一個(gè)新拍攝的圖像傳感器照片,輸入緩沖區(qū)地址將指向那里。所有內(nèi)容都存儲(chǔ)在NPU內(nèi)部的超大緩存中。從那以后就沒(méi)有DRAM交互了。 高速緩存的容量為32 MiB,并且是高度存儲(chǔ)的,每個(gè)bank只有一個(gè)端口。特斯拉指出,有一個(gè)復(fù)雜的bank仲裁器,連同一些編譯器提示,用于減少bank沖突。每個(gè)周期中,最多可以將256個(gè)字節(jié)的數(shù)據(jù)讀取到數(shù)據(jù)緩沖區(qū)中,并且最多可以將128個(gè)字節(jié)的權(quán)重讀取到權(quán)重緩沖區(qū)中。根據(jù)步幅的不同,NPU可以在操作開(kāi)始之前將多行數(shù)據(jù)引入數(shù)據(jù)緩沖區(qū),以便更好地重用數(shù)據(jù)。每個(gè)NPU的組合讀取帶寬為384B/cycle,其本地緩存的峰值讀取帶寬為786 GB/s。特斯拉說(shuō),這使他們能夠非常接近維持MAC正常運(yùn)行所需的理論帶寬峰值,通常至少80%的利用率,很多時(shí)候會(huì)達(dá)到更高的利用率。
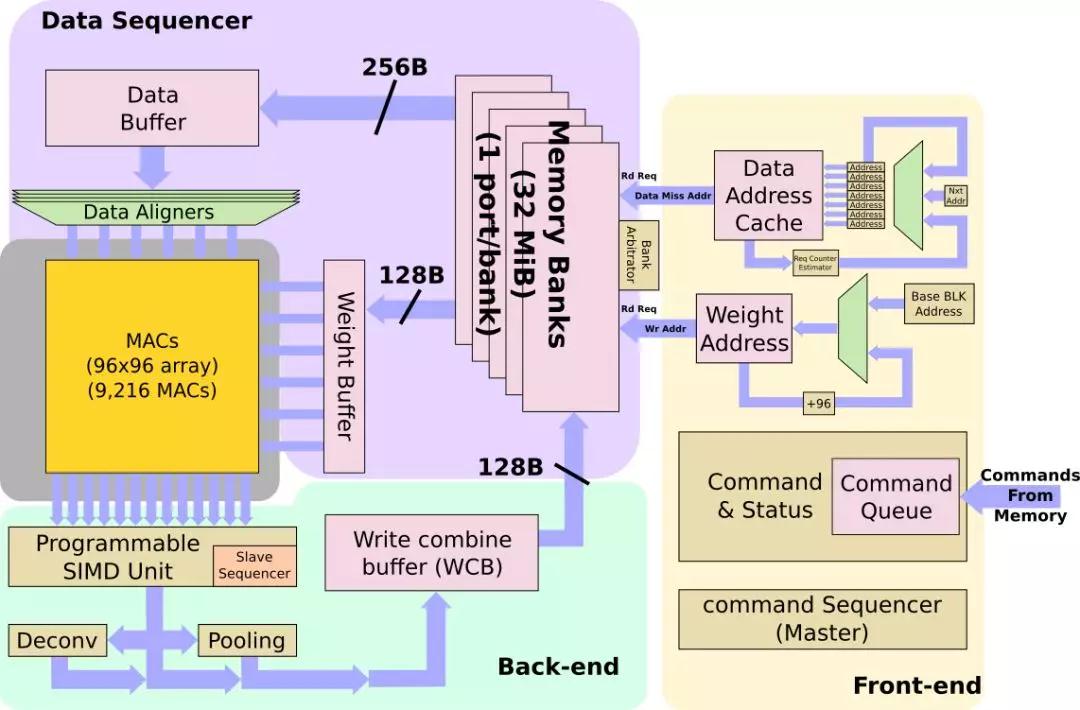
MAC陣列
CNNs的主要操作當(dāng)然是卷積,卷積占特斯拉軟件在NPU上執(zhí)行的所有操作的98.1%,反卷積占1.6%。在優(yōu)化MAC上花費(fèi)了大量的精力。 MAC陣列中的數(shù)據(jù)重用很重要,否則,即使每秒1 TB的帶寬也無(wú)法滿足要求。在某些設(shè)計(jì)中,為了提高性能,可以一次處理多張圖像。但是,出于安全原因,延遲是其設(shè)計(jì)的關(guān)鍵屬性,因此它們必須盡快處理單個(gè)圖像。特斯拉在這里做了許多其他優(yōu)化。NPU通過(guò)合并輸出通道中X和Y維度上的輸出像素,在多個(gè)輸出通道上并行運(yùn)行。這允許他們并行化工作,并同時(shí)處理96個(gè)像素。換句話說(shuō),當(dāng)它們處理通道中的所有像素時(shí),所有輸入權(quán)重都是共享的。此外,它們還交換輸出通道和輸入通道循環(huán)(請(qǐng)參見(jiàn)下圖的代碼段)。這使它們能夠依次處理所有輸出通道,共享所有輸入激活,而無(wú)需進(jìn)一步的數(shù)據(jù)移動(dòng)。這是帶寬需求的又一個(gè)很好的降低。
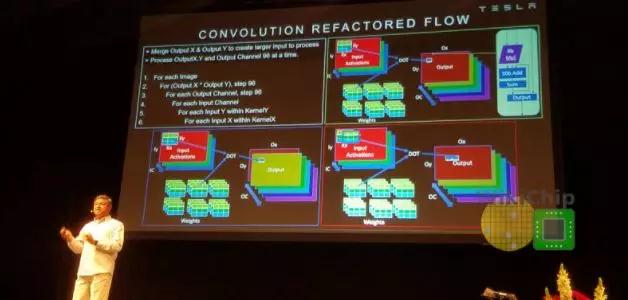
通過(guò)上述優(yōu)化,可以簡(jiǎn)化MAC陣列操作。每個(gè)陣列包括9,216個(gè)MAC,并排列在96 x 96的獨(dú)立單周期MAC反饋環(huán)路的單元中(請(qǐng)注意,這不是收縮陣列,單元間沒(méi)有數(shù)據(jù)移位)。為了簡(jiǎn)化其設(shè)計(jì)并降低功耗,它們的MAC由8位乘8位整數(shù)乘法和32位整數(shù)加法組成。特斯拉自己的模型在發(fā)送給客戶時(shí)都是預(yù)先量化的,因此芯片只存儲(chǔ)8位整數(shù)中的所有數(shù)據(jù)和權(quán)重。 每個(gè)周期,輸入數(shù)據(jù)的底部一行和權(quán)值的最右邊一列將在整個(gè)MAC數(shù)組中公示。每個(gè)單元獨(dú)立執(zhí)行適當(dāng)?shù)某朔ɡ奂舆\(yùn)算。在下一個(gè)循環(huán)中,輸入數(shù)據(jù)將一行向下推,而權(quán)重網(wǎng)格將一行向右推。這個(gè)過(guò)程是重復(fù)的,輸入數(shù)據(jù)的最底一行和權(quán)值的最右列在數(shù)組中公示。單元繼續(xù)獨(dú)立執(zhí)行其操作。全點(diǎn)積卷積結(jié)束時(shí),MAC陣列每次下移96個(gè)元素,這也是SIMD單元的吞吐量。
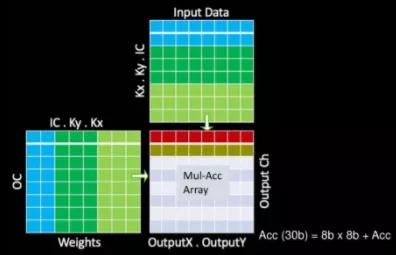
NPU本身實(shí)際上能夠運(yùn)行超過(guò)2 GHz的速度,盡管特斯拉引用了所有基于2 GHz時(shí)鐘的數(shù)字,所以可以推測(cè),這就是生產(chǎn)時(shí)鐘。在2GHz下運(yùn)行,則每個(gè)NPU的峰值計(jì)算性能為36.86 teraOPS (Int8)。NPU的總功耗為7.5 W,約占FSD功耗預(yù)算的21%。這使得它們的性能功率效率約為4.9TOPs/W,這是迄今為止我們?cè)谝殉鲐浶酒纤?jiàn)過(guò)的最高效率之一,與英特爾最近宣布的NNP-I (Spring Hill)推理加速器不相上下。盡管特斯拉NPU在實(shí)際中的通用性有點(diǎn)可疑。但請(qǐng)注意,每個(gè)芯片上有兩個(gè)NPU,它們消耗的總功率預(yù)算略超過(guò)40%。
SIMD單元
從MAC陣列,將一行壓入SIMD單元。SIMD單元是可編程執(zhí)行單元,旨在為特斯拉提供一些額外的靈活性。為此,SIMD單元為諸如sigmoid,tanh,argmax和其他各種功能提供支持。它帶有自己豐富的指令集,這些指令由從機(jī)命令定序器執(zhí)行。從命令排序器從前面描述的指令的擴(kuò)展槽中獲取操作。特斯拉表示,它支持你在普通CPU中可以找到的大多數(shù)典型指令。
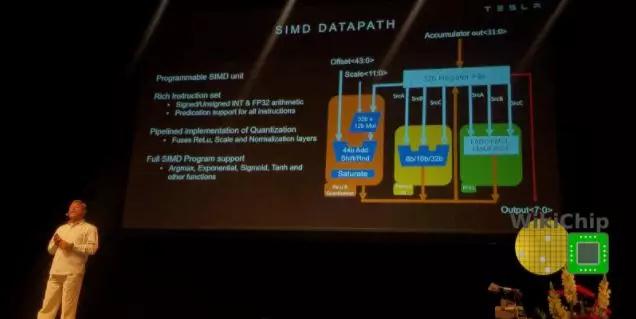
將結(jié)果從SIMD單元轉(zhuǎn)發(fā)到pooling unit(如果需要),或者直接轉(zhuǎn)發(fā)到write-combine,在write-combine中,結(jié)果會(huì)以128B/周期的速率被機(jī)會(huì)性地寫(xiě)回SRAM。該單元進(jìn)行2×2和3×3的池操作,在conv單元中進(jìn)行更高階的處理。它可以進(jìn)行最大池化和平均池化。對(duì)于平均池,使用基于2×2/3×3的常量的定點(diǎn)乘法單元替換除法。

總而言之,特斯拉實(shí)現(xiàn)了它的性能目標(biāo)。FSD計(jì)算機(jī)(HW 3.0)的性能比上一代(HW 2.5)提高了21倍,而功耗只提高了25%。



京公網(wǎng)安備110402500036號(hào)
© 中國(guó)科學(xué)院微電子研究所 版權(quán)所有
地址:北京市朝陽(yáng)區(qū)北土城西路3號(hào) 郵編:100029
郵箱:icac@ime.ac.cn
學(xué)習(xí)園地