
中國科學院自動化研究所智能交互團隊在環(huán)境魯棒性、輕量級建模、自適應能力以及端到端處理等幾個方面進行持續(xù)攻關,在語音識別方面獲新進展,相關成果將在全球語音學術會議INTERSPEECH2019發(fā)表。
現(xiàn)有端到端語音識別系統(tǒng)難以有效利用外部文本語料中的語言學知識,針對這一問題,陶建華、易江燕、白燁等人提出采用知識遷移的方法,首先對大規(guī)模外部文本訓練語言模型,然后將該語言模型中的知識遷移到端到端語音識別系統(tǒng)中。這種方法利用了外部語言模型提供詞的先驗分布軟標簽,并采用KL散度進行優(yōu)化,使語音識別系統(tǒng)輸出的分布與外部語言模型輸出的分布接近,從而有效提高語音識別的準確率。
語音關鍵詞檢測在智能家居、智能車載等場景中有著重要作用。面向終端設備的語音關鍵詞檢測對算法的時間復雜度和空間復雜度有著很高的要求。當前主流的基于殘差神經(jīng)網(wǎng)絡的語音關鍵詞檢測,需要20萬以上的參數(shù),難以在終端設備上應用。為了解決這一問題,陶建華、易江燕、白燁等人提出基于共享權值自注意力機制和時延神經(jīng)網(wǎng)絡的輕量級語音關鍵詞檢測方法。該方法采用時延神經(jīng)網(wǎng)絡進行降采樣,通過自注意力機制捕獲時序相關性;并采用共享權值的方法,將自注意力機制中的多個矩陣共享,使其映射到相同的特征空間,從而進一步壓縮了模型的尺寸。與目前的性能最好的基于殘差神經(jīng)網(wǎng)絡的語音關鍵詞檢測模型相比,他們提出的方法在識別準確率接近的前提下,模型大小僅為殘差網(wǎng)絡模型的1/20,有效降低了算法復雜度。
針對RNN-Transducer模型存在收斂速度慢、難以有效進行并行訓練的問題,陶建華、易江燕、田正坤等人提出了一種Self-attention Transducer (SA-T)模型,主要在以下三個方面實現(xiàn)了改進:(1)通過自注意力機制替代RNN進行建模,有效提高了模型訓練的速度;(2)為了使SA-T能夠進行流式的語音識別和解碼,進一步引入了Chunk-Flow機制,通過限制自注意力機制范圍對局部依賴信息進行建模,并通過堆疊多層網(wǎng)絡對長距離依賴信息進行建模;(3)受CTC-CE聯(lián)合優(yōu)化啟發(fā),將交叉熵正則化引入到SA-T模型中,提出Path-Aware Regularization(PAR),通過先驗知識引入一條可行的對齊路徑,在訓練過程中重點優(yōu)化該路徑。經(jīng)驗證,上述改進有效提高了模型訓練速度及識別效果。
語音分離又稱為雞尾酒會問題,其目標是從同時含有多個說話人的混合語音信號中分離出不同說話人的信號。當一段語音中同時含有多個說話人時,會嚴重影響語音識別和說話人識別的性能。目前解決這一問題的兩種主流方法分別是:深度聚類(DC, deep clustering)算法和排列不變性訓練(PIT, permutation invariant training)準則算法。深度聚類算法在訓練過程中不能以真實的干凈語音作為目標,性能受限于k-means聚類算法;而PIT算法其輸入特征區(qū)分性不足。針對DC和PIT算法的局限性,陶建華、劉斌、范存航等人提出了基于區(qū)分性學習和深度嵌入式特征的語音分離方法。首先,利用DC提取一個具有區(qū)分性的深度嵌入式特征,然后將該特征輸入到PIT算法中進行語音分離。同時,為了增大不同說話人之間的距離,減小相同說話人之間的距離,引入了區(qū)分性學習目標準則,進一步提升算法的性能。所提方法在WSJ0-2mix語音分離公開數(shù)據(jù)庫上獲得較大的性能提升。
端到端系統(tǒng)在語音識別中取得突破。然而在復雜噪聲環(huán)境下,端到端系統(tǒng)的魯棒性依然面臨巨大挑戰(zhàn)。針對端到端系統(tǒng)不夠魯棒的問題,劉文舉、聶帥、劉斌等人提出了基于聯(lián)合對抗增強訓練的魯棒性端到端語音識別方法。具體地說,使用一個基于mask的語音增強網(wǎng)絡、基于注意力機制的端到端語音識別網(wǎng)絡和判別網(wǎng)絡的聯(lián)合優(yōu)化方案。判別網(wǎng)絡用于區(qū)分經(jīng)過語音增強網(wǎng)絡之后的頻譜和純凈語音的頻譜,可以引導語音增強網(wǎng)絡的輸出更加接近純凈語音分布。通過聯(lián)合優(yōu)化識別、增強和判別損失,神經(jīng)網(wǎng)絡自動學習更為魯棒的特征表示。所提方法在aishell-1數(shù)據(jù)集上面取得了較大的性能提升。
說話人提取是提取音頻中目標說話人的聲音。與語音分離不同,說話人提取不需要分離出音頻中所有說話人的聲音,而只關注某一特定說話人。目前主流的說話人提取方法是:說話人波束(SpeakerBeam)和聲音濾波器(Voice filter)。這兩種方法都只關注聲音的頻譜特征,而沒有利用多通道信號的空間特性。因為聲源是有方向性的,并且在實際環(huán)境中是空間可分的。所以,如果正確利用多通道的空間區(qū)分性,說話人提取系統(tǒng)可以更好地估計目標說話人。為了有效利用多通道的空間特性,劉文舉、梁山、李冠君等人提出了方向感知的多通道說話人提取方法。首先多通道的信號先經(jīng)過一組固定波束形成器,來產(chǎn)生不同方向的波束。進而DNN采用attention機制來確定目標信號所在的方向,來增強目標方向的信號。最后增強后的信號經(jīng)過SpeakerBeam通過頻譜線索來提取目標信號。提出的算法在低信噪比或同性別說話人混合的場景中性能提升明顯。
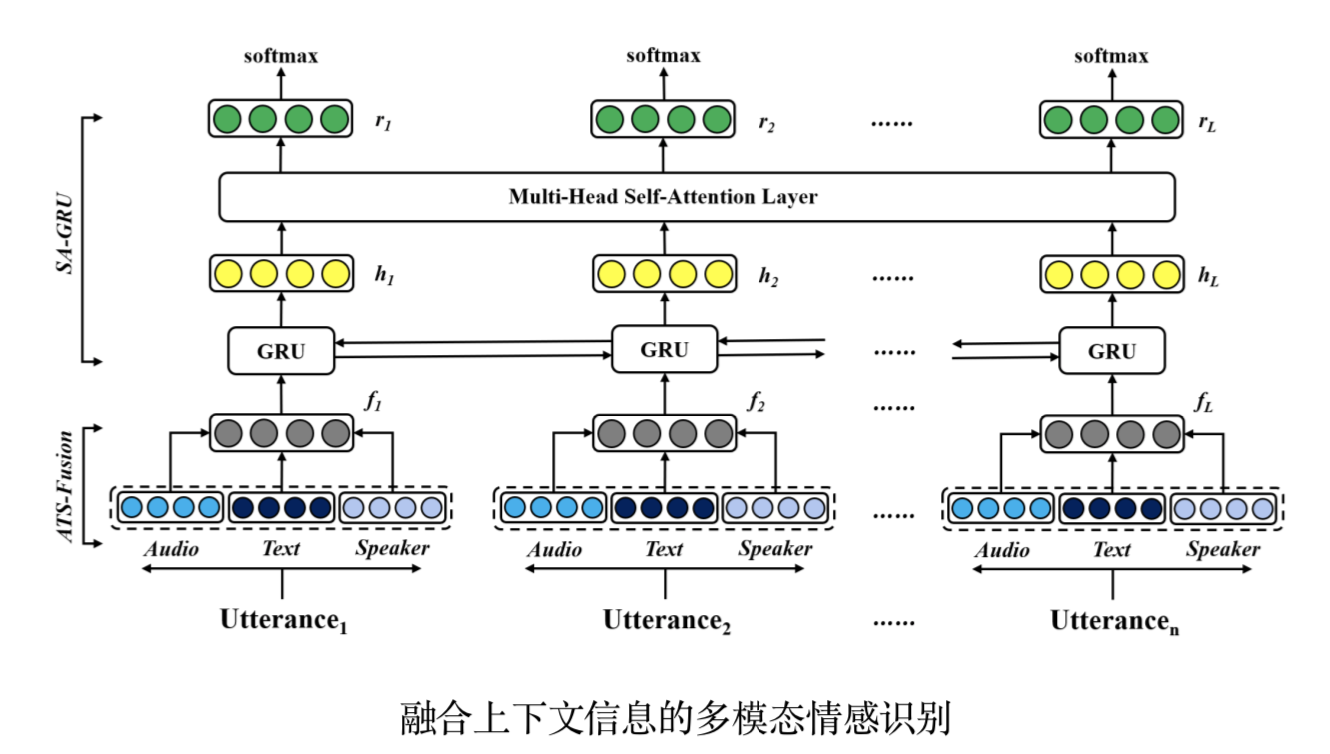
傳統(tǒng)的對話情感識別方法通常從孤立的句子中識別情感狀態(tài),未能充分考慮對話中的上下文信息對于當前時刻情感狀態(tài)的影響。針對這一問題,陶建華、劉斌、連政等人提出了一種融合上下文信息的多模態(tài)情感識別方法。在輸入層,采用注意力機制對文本特征和聲學特征進行融合;在識別層,采用基于自注意力機制的雙向循環(huán)神經(jīng)網(wǎng)絡對長時上下文信息進行建模;為了能夠有效模擬真實場景下的交互模式,引入身份編碼向量作為額外的特征輸入到模型,用于區(qū)分交互過程中的身份信息。在IEMOCAP情感數(shù)據(jù)集上對算法進行了評估,實驗結果表明,該方法相比現(xiàn)有最優(yōu)基線方法,在情感識別性能上提升了2.42%。
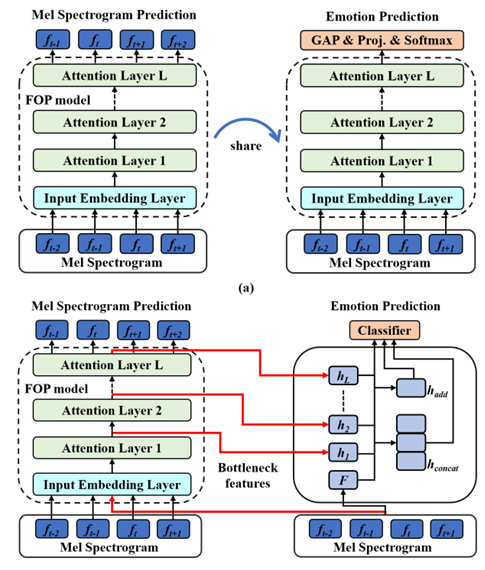
由于情感數(shù)據(jù)標注困難,語音情感識別面臨著數(shù)據(jù)資源匱乏的問題。雖然采用遷移學習方法,將其他領域知識遷移到語音情感識別,可以在一定程度上緩解低資源的問題,但是這類方法并沒有關注到長時信息對語音情感識別的重要作用。針對這一問題,陶建華、劉斌、連政等人提出了一種基于未來觀測預測(Future Observation Prediction, FOP)的無監(jiān)督特征學習方法。FOP采用自注意力機制,能夠有效捕獲長時信息;采用微調(diào)(Fine-tuning)和超列(Hypercolumns)兩種遷移學習方法,能夠?qū)OP學習到的知識用于語音情感識別。該方法在IEMOCAP情感數(shù)據(jù)集上的性能超過了基于無監(jiān)督學習策略的語音情感識別。
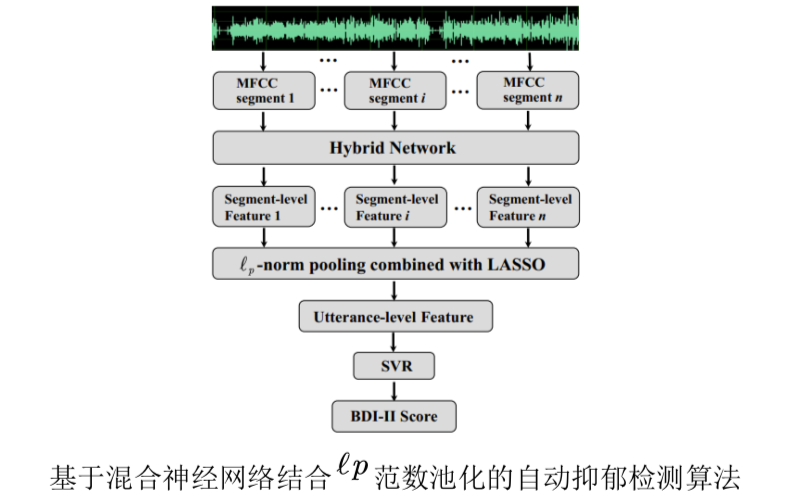
相關生理學研究表明,MFCC (Mel-frequency cepstral coefficient)對于抑郁檢測來說是一種有區(qū)分性聲學特征,這一研究成果使得不少工作通過MFCC來辨識個體的抑郁程度。但是,上述工作中很少使用神經(jīng)網(wǎng)絡來進一步捕獲MFCC中反映抑郁程度的高表征特征;此外,針對抑郁檢測這一問題,合適的特征池化參數(shù)未能被有效優(yōu)化。針對上述問題,陶建華、劉斌、牛明月等人提出了一種混合網(wǎng)絡并結合LASSO (least absolute shrinkage and selection operator)的lp范數(shù)池化方法來提升抑郁檢測的性能。首先將整段音頻的MFCC切分成具有固定大小的長度;然后將這些切分的片段輸入到混合神經(jīng)網(wǎng)絡中以挖掘特征序列的空間結構、時序變化以及區(qū)分性表示與抑郁線索相關的信息,并將所抽取的特征記為段級別的特征;最后結合LASSO的lp范數(shù)池化將這些段級別的特征進一步聚合為表征原始語音句子級的特征。
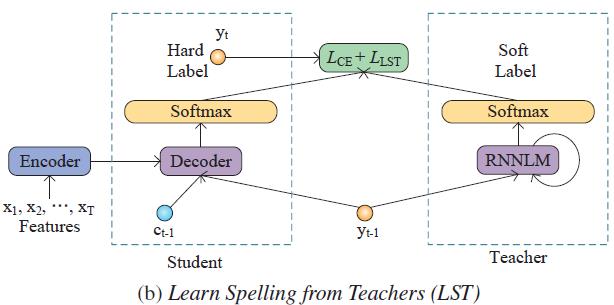
基于知識遷移的端到端語音識別系統(tǒng)
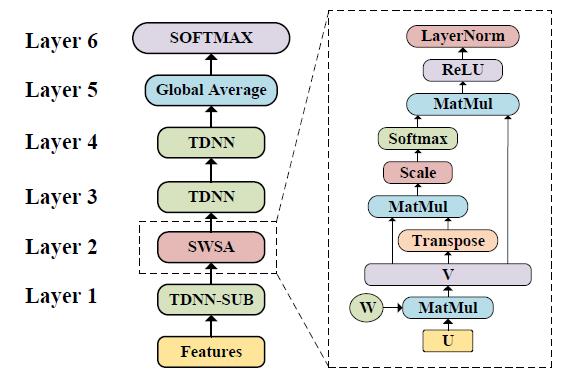
基于共享權值自注意力機制和時延神經(jīng)網(wǎng)絡的輕量級語音關鍵詞檢測
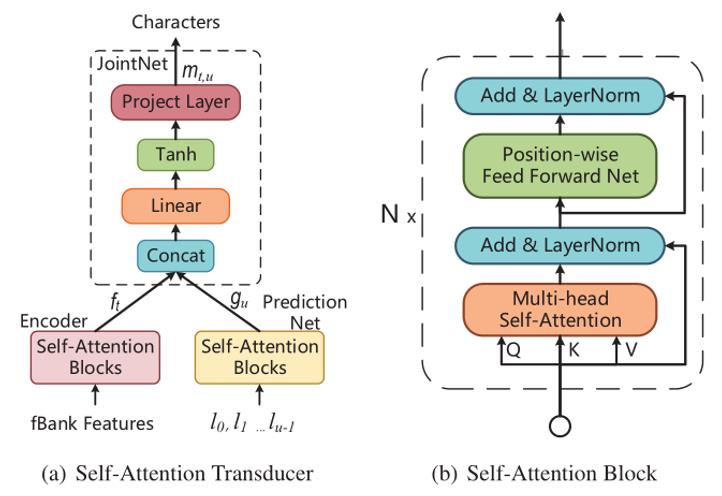
基于自注意力機制的端到端語音轉(zhuǎn)寫模型

基于區(qū)分性學習和深度嵌入式特征的語音分離方法總體框圖
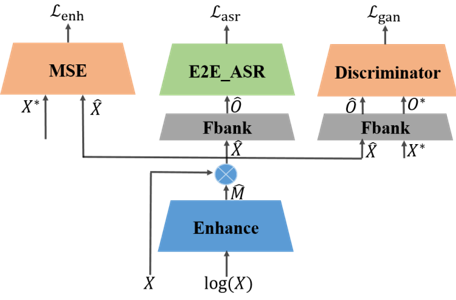
基于聯(lián)合對抗增強訓練的魯棒性端到端語音識別總體框圖
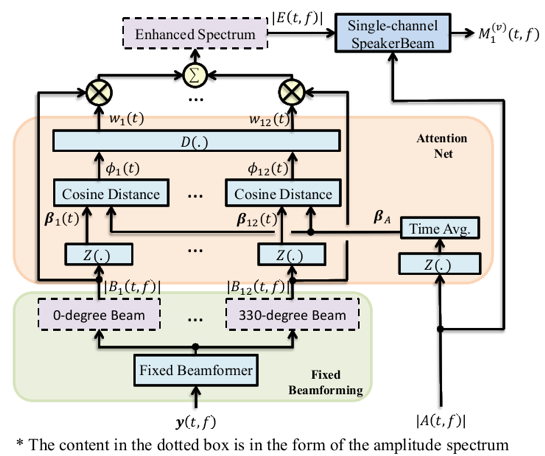
方向感知的多通道說話人提取方法框圖


京公網(wǎng)安備110402500036號
© 中國科學院微電子研究所 版權所有
地址:北京市朝陽區(qū)北土城西路3號 郵編:100029
郵箱:icac@ime.ac.cn
學習園地