脈沖神經(jīng)網(wǎng)絡(luò)(SNNs)具有事件驅(qū)動(dòng)、低能耗的特性,非常適合在自動(dòng)駕駛、移動(dòng)醫(yī)療等邊緣計(jì)算場(chǎng)景中部署。在現(xiàn)實(shí)應(yīng)用中,由于用戶數(shù)據(jù)存在場(chǎng)景偏差,預(yù)訓(xùn)練的 SNN 模型往往難以直接適配個(gè)性化任務(wù)。盡管設(shè)備端訓(xùn)練被視為一種可行的解決路徑,但在資源有限的邊緣硬件上實(shí)現(xiàn)高效率、低功耗的訓(xùn)練,仍面臨顯著挑戰(zhàn)。
針對(duì)上述問題,中國科學(xué)院微電子研究所集成電路制造技術(shù)全國重點(diǎn)實(shí)驗(yàn)室研究團(tuán)隊(duì),通過算法與硬件協(xié)同設(shè)計(jì),在小批次學(xué)習(xí)場(chǎng)景下實(shí)現(xiàn)了邊緣端脈沖神經(jīng)網(wǎng)絡(luò)的高能效訓(xùn)練。團(tuán)隊(duì)提出了一種硬件友好的訓(xùn)練算法——脈沖直連反饋對(duì)齊(SDFA),在誤差反向傳播過程中構(gòu)建了直連反饋路徑,其中反饋權(quán)重采用全隨機(jī)矩陣,且在訓(xùn)練過程中保持固定,無需更新,大幅降低了計(jì)算與存儲(chǔ)開銷。在硬件層面,團(tuán)隊(duì)設(shè)計(jì)了名為 PipeSDFA 的高效憶阻存內(nèi)計(jì)算架構(gòu),充分利用 SDFA 的算法特性,實(shí)現(xiàn)了時(shí)間步、數(shù)據(jù)與批處理的三級(jí)流水線并行處理。該架構(gòu)還借助憶阻器件的本征隨機(jī)性,高效存儲(chǔ)固定的隨機(jī)反饋矩陣。為進(jìn)一步提升計(jì)算能效,團(tuán)隊(duì)引入了輸入數(shù)據(jù)復(fù)用機(jī)制,并提出了高效權(quán)重映射方案(vw-SDK),有效優(yōu)化了計(jì)算資源的利用。實(shí)驗(yàn)結(jié)果表明,SDFA 算法在多個(gè)數(shù)據(jù)集上保持了與基線方法相當(dāng)?shù)哪P途龋瑩p失不超過 2%。在硬件效能方面,PipeSDFA 架構(gòu)相比已有的 RRAM-CIM 架構(gòu)(如 PipeLayer),計(jì)算速度提升1.1~10.5倍,能效比提升 1.37~2.1倍。這一研究結(jié)果有效解決了邊緣設(shè)備訓(xùn)練中的硬件效率瓶頸,為神經(jīng)形態(tài)計(jì)算系統(tǒng)在資源受限環(huán)境中的實(shí)際應(yīng)用提供了可擴(kuò)展的解決方案。
此項(xiàng)研究結(jié)果以 “When Pipelined In-Memory Accelerators Meet Spiking Direct Feedback Alignment: A Co-Design for Neuromorphic Edge Computing”為題在德國慕尼黑舉辦的第44屆國際計(jì)算機(jī)輔助設(shè)計(jì)會(huì)議(ICCAD)上進(jìn)行了口頭報(bào)告。微電子所碩士研究生任浩雄為第一作者,微電子所尚大山研究員為通訊作者。該工作得到了國家重點(diǎn)研發(fā)計(jì)劃、國家自然科學(xué)基金和中國科學(xué)院的支持。
國際計(jì)算機(jī)輔助設(shè)計(jì)會(huì)議ICCAD(IEEE/ACM International Conference on Computer-Aided Design)由美國計(jì)算機(jī)協(xié)會(huì)(ACM)和電氣與電子工程師協(xié)會(huì)(IEEE)聯(lián)合主辦,是全球電子設(shè)計(jì)自動(dòng)化(EDA)與集成電路設(shè)計(jì)領(lǐng)域歷史悠久、影響力深遠(yuǎn)的頂級(jí)學(xué)術(shù)會(huì)議之一。會(huì)議聚焦芯片設(shè)計(jì)自動(dòng)化、存內(nèi)計(jì)算、AI 架構(gòu)等前沿方向,吸引了全球頂尖科研團(tuán)隊(duì)與半導(dǎo)體企業(yè)的廣泛關(guān)注。
文章鏈接:https://doi.org/10.1109/ICCAD66269.2025.11240745
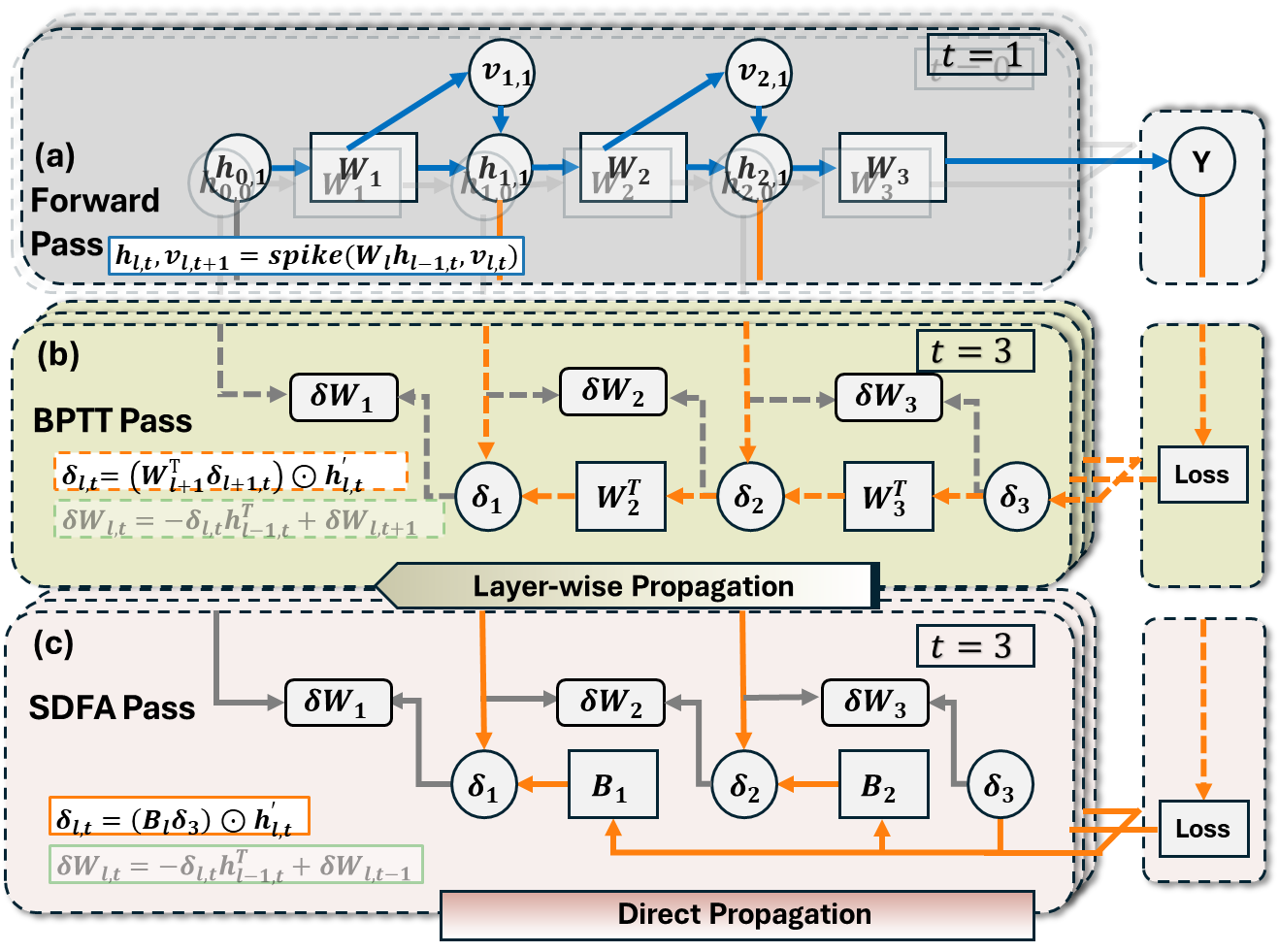
圖1?脈沖直連反饋對(duì)齊算法(SDFA)流程圖
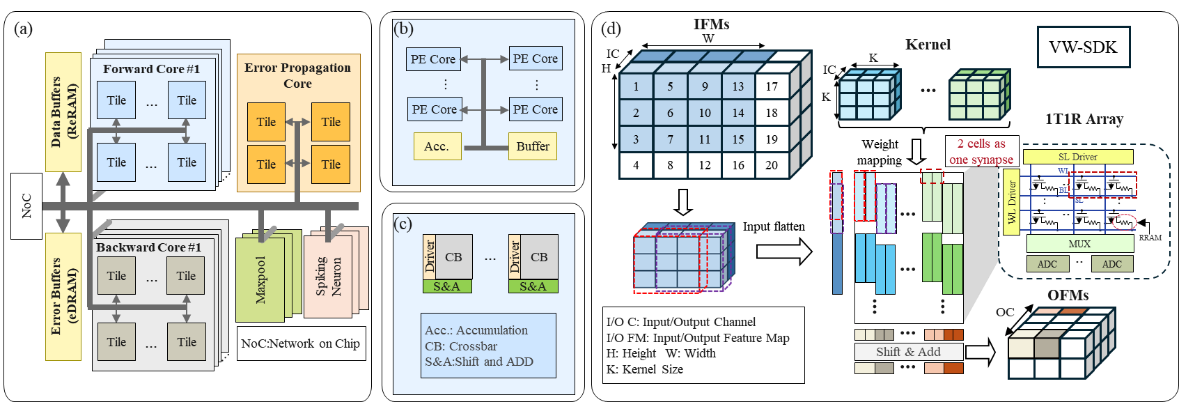
圖2?存內(nèi)計(jì)算架構(gòu)
綜合信息