隨著芯片工藝制造的進步,工藝制程逐漸接近物理極限,深度神經(jīng)網(wǎng)絡(luò)的發(fā)展使得計算量和參數(shù)量呈指數(shù)上升,阻變存儲器應(yīng)用于大規(guī)模神經(jīng)網(wǎng)絡(luò)面臨多個個挑戰(zhàn):1)由于卷積神經(jīng)網(wǎng)絡(luò)權(quán)值數(shù)量不斷增加,使得阻變存儲器的面積開銷越來越大;2)對于多值大規(guī)模阻變存儲器陣列,當(dāng)參與乘累加計算的阻變單元數(shù)量很大時,由于阻變單元電導(dǎo)漂移而引起的誤差累積更嚴(yán)重;3)三維阻變存儲器陣列由于制造工藝難度更大,使得阻變單元與電路協(xié)同設(shè)計實現(xiàn)困難。
針對上述問題,微電子研究所重點實驗室劉明院士團隊研發(fā)了基于三維阻變存儲器存內(nèi)計算宏芯片。科研人員將多值自選通(Multi-level self-selective,MLSS)三維垂直阻變存儲器與抗漂移多位模擬輸入權(quán)值乘(ADINWM)方案相結(jié)合,實現(xiàn)了高密度計算;在抗漂移多位模擬輸入權(quán)值乘方案基礎(chǔ)上提出了電流幅值離散整形(CADS)電路用于增加讀出電流的感知容限(SM)用于后續(xù)精確的模擬乘法計算,解決了由于三維阻變存儲器陣列單元電導(dǎo)波動引起的在傳統(tǒng)并行字線輸入原位乘累加方案下不可恢復(fù)的讀出電流失真;采用nA級操作電流的三維垂直阻變存儲器陣列降低系統(tǒng)功耗,同時引入具有柵預(yù)充電開關(guān)跟隨器(GPSF)的模擬乘法器與直接小電流模數(shù)轉(zhuǎn)換器降低延時。當(dāng)輸入、權(quán)重和輸出數(shù)據(jù)分別為8位、9位和22位時,位密度為58.2 bit/μm–2,能效為8.32 TOPS/W。與傳統(tǒng)方法相比,提供了更準(zhǔn)確的大腦MRI邊緣檢測和更高的CIFAR-10數(shù)據(jù)集推理精度。
上述研究成果以“A Computing-in-memory macro with three dimensional resistive random-access memory”為題在電子學(xué)領(lǐng)域國際頂級期刊《自然-電子學(xué)》(Nature Electronics)上在線發(fā)表,實現(xiàn)了中科院微電子所在Nature大類子刊零的突破。微電子所霍強博士為第一作者,北京理工大學(xué)楊鎰銘為共同第一作者,微電子所張鋒研究員和北京理工大學(xué)王興華副教授為共同通訊作者。
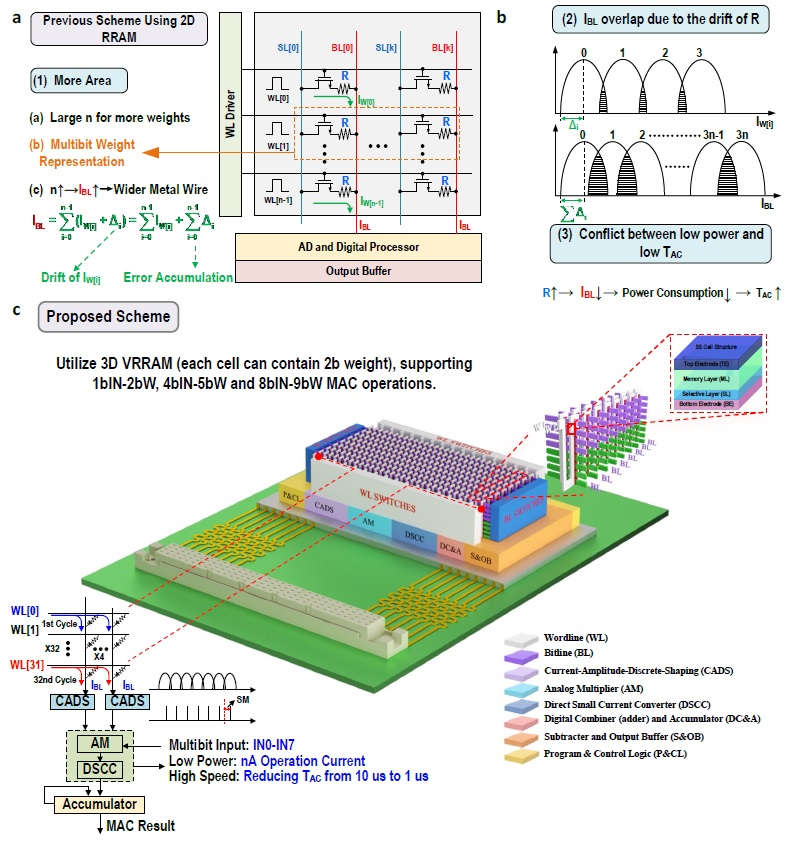
圖1. 2D RRAM應(yīng)用于大型3D CNN的挑戰(zhàn)及所提出的三維計算方案。a、更多的權(quán)重、多位權(quán)重表示和更寬的金屬線引入更多設(shè)計難題 b、讀出電流的挑戰(zhàn)是交疊及低功耗和低延遲之間的矛盾。c、基于MLSS 3D VRRAM的高精度非易失存內(nèi)計算方案。借助CADS電路的ADINWM方案可以有效緩解傳統(tǒng)PWIVMM方案引起的電流交疊,提高推理精度。基于集成3D VRRAM芯片的CIM宏的實現(xiàn)闡述了執(zhí)行CNN邊緣計算的完整解決方案。
原文鏈接:https://www.nature.com/articles/s41928-022-00795-x
綜合信息